以为视觉生成在做内容,其实它在逼近全模态世界模型

2026年的具身智能,正站在“热”与“透”的分水岭上。
热是真热——2026年开年以来,中国具身智能赛道上演资本核爆,接连出现过亿美元级种子轮融资,以及刷新认知的超大额Pre-A融资,连续打破行业单轮与阶段纪录。资本的密集涌入,让这个赛道迅速升温。但热闹背后,机器人一旦离开实验室进入真实环境,能力边界立刻现形:换个光照、改个布局,成功率就肉眼可见地往下掉。机器人的“身体”进步飞快,但“理解力”还差得远。
而“理解力”的卡点,通常被归结为“数据荒”。一边是机器人产量高速增长,另一边高质量物理交互数据仍停留在极小规模,远低于行业所需。更关键的是两组矛盾:标准化与多样性难以兼得,数据虽干净却失真;精度与真实性彼此掣肘,动捕数据存在“vision gap”。再叠加数据孤岛,问题被进一步放大。
然而,只看到“数据荒”仍说浅了。具身智能真正的深层病灶,是“理解浅”——模型是否具备对真实物理世界进行统一建模的能力?
这种“统一”,本质上是对空间与时间的同时建模:既要刻画世界在某一时刻的状态,也要理解状态如何随时间持续演化。换句话说,机器人面对的并不是孤立的图像或视频,而是一个不断变化的动态系统——图像作为基底、提供瞬时的空间结构,视频则承载这种结构在时间中的连续变化与因果展开。缺乏对单帧空间的精确刻画,时序推演难以稳定;而没有时间维度的连续建模,再精细的空间理解也无法真正落到对现实世界的把握。
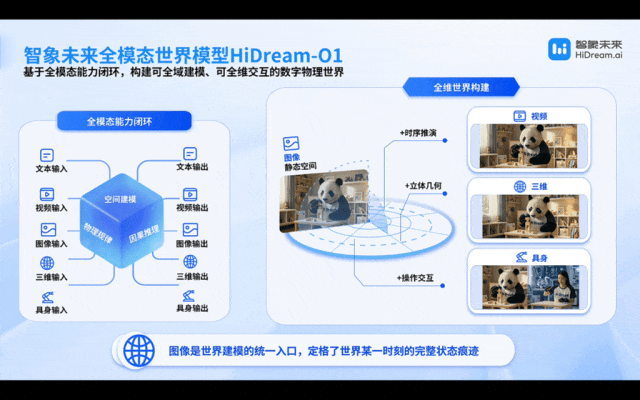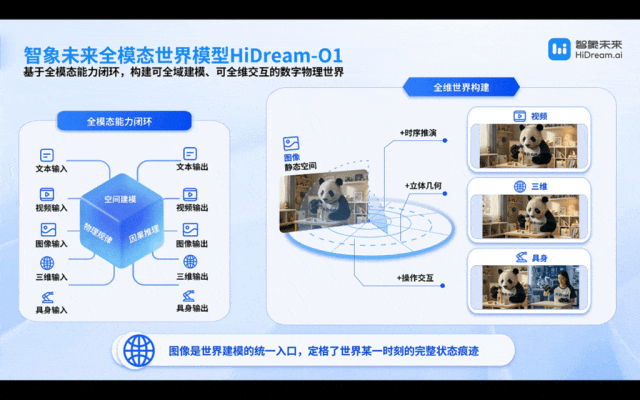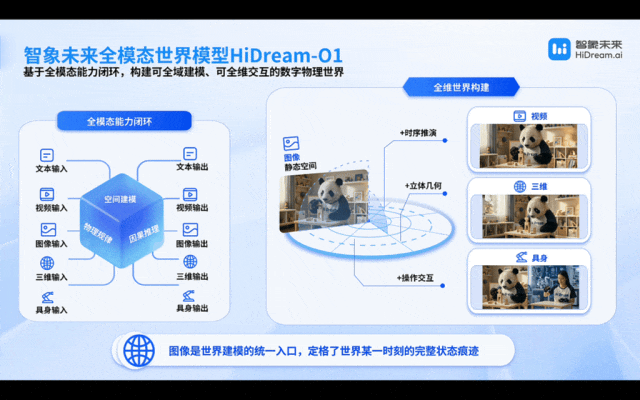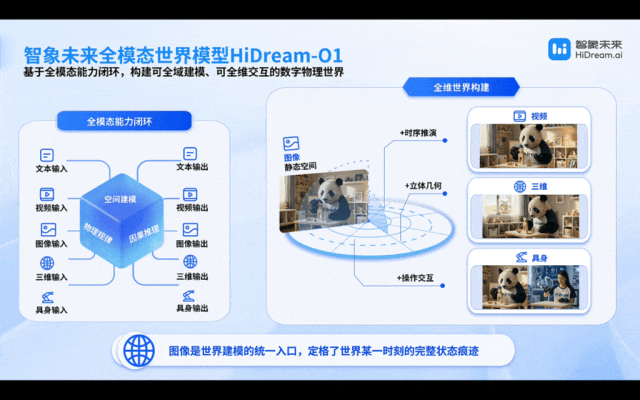
问题在于,真实世界并不会按这种“理想建模方式”稳定展开:光影、空间、物体状态与任务随时变化,因果链条不断分岔。机器人不仅要“看见”,更要理解“为何如此”以及“接下来会如何演化”。但当前范式仍停留在“喂例子”,模型学到的多是画面与动作的表层对应,而非物理规律与因果结构,一旦环境发生轻微偏移,泛化能力便迅速失效。
因此,具身智能真正需要的,并不是一个更大的数据仓库,而是一套能够在数据之上运行的“世界”。一个可以表达世界状态、推演物理过程、并在偏差中自我修正的模型体系。
数据解决的是“见多识广”,而世界模型要解决的是“一叶知秋”——让机器人不仅见过足够多的房间,更能在“脑海中运行一个房间”,对尚未发生的变化进行预测与决策。
走出这场隐形的“饥荒”,需要的不只是数据规模的扩张,而是一场从感知到认知、从记录世界到建模世界的范式跃迁。
01 融合破局:生成数据,倒逼“理解”
面对“数据荒”和“理解浅”这两个同时存在的难题,智象未来作为一家研发新一代原生全模态世界模型的AI创企,正在走一条和传统多模态模型完全不同的路线。
它的核心能力,并不只是“会生成图像或视频”,而是创新性地围绕“统一架构”搭建了一整套底层模型体系。这个体系的关键在于:把图像、视频、动作、物理信号放进同一个建模空间里统一处理,从而让模型具备更接近“真实世界”的表达方式。这也为它进入具身智能这种更复杂的场景打下了基础。
2026年,智象未来与诺亦腾机器人达成战略合作。这一合作并不是简单的数据交换,而是一次新的尝试:把真实世界的高精度动作捕捉能力,与AI的视觉生成能力结合起来,用“生成”的方式生产训练数据。

在这套流程中,诺亦腾提供的是基于动捕系统采集的人体动作与物理交互数据。这些数据来自穿戴式设备对人体运动的精细记录,精度可以达到毫米级,每一个细微的移动和角度变化,都对应真实的物理动作。
但真正的难点也在这里出现。
当这些高精度动作数据被用来做视频或场景生成时,生成过程必须做到一件非常苛刻的事情:不能“生成偏了”。不仅不能引入新的误差,还不能在扩展更多场景时把原本的误差放大,否则这些数据就无法用于机器人学习,因为它们已经不再“真实可信”。
问题也因此被推到更底层:关键不再是“能生成多少数据”,而是“生成系统本身能不能保证物理是对的”。
这一点,直接把不同技术路线的差异拉开了。
在目前主流多模态方案中,以DiT(Diffusion Transformer)为代表的架构,基本思路是把图像、视频、文本、动作分别编码,然后再在一个隐空间里做融合。
这种方式的问题在于,它默认了一件事:世界可以先拆开理解,再拼起来。
但真实世界并不是这样运作的。
空间结构、时间变化、物理交互,其实是同一个世界的不同表现方式。如果先拆开处理再去融合,就很容易丢信息、产生断裂,最终结果就是:模型可以“生成看起来像世界的东西”,但很难真正理解世界是怎么运作的。
随着任务越来越复杂,这条路线也越来越依赖两件事:更多数据、更多算力,但始终难以突破对真实物理一致性的上限。
相比之下,智象未来最新提出的UiT(Unified Transformer)原生全模态架构,从一开始就不是在“优化这种方法”,而是在重新定义方法本身。
所谓“原生全模态”,关键不在于支持多少种数据,而在于不再把模态当成不同的东西来处理。
在UiT中,图像、视频、文本、动作和传感器信息,不再分别编码,而是以更接近原始信号的形式,直接进入同一个模型空间。
在这个空间里,它们不再是不同类型的数据,而是同一个世界在不同维度上的表达。
换句话说,模型不再分别学习“图像是什么”“视频是什么”“动作是什么”,再去拼在一起,而是在同一个系统里同时理解三件事:空间是什么样、时间怎么变化、以及物理是如何发生的。
用智象未来创始人梅涛博士的判断来说,这才是世界模型成立的基础:真正的世界模型,不是把多种能力叠加起来,而是必须有一个统一的底层结构,让世界可以被表达、被推演,甚至被重建。
如果没有这个统一底座,所谓“理解世界”,本质上只是不同模型之间的结果对齐,而不是对同一个世界的统一建模。
智象未来联合创始人兼CTO姚霆博士进一步强调,图像本身并不是独立能力,而是世界在某一瞬间的空间“切片”;视频、3D和人的动作,则是这个切片在时间和交互中的展开。
所以它们不是互相独立的模态,而是同一个世界在不同维度的展开方式。只有在统一架构里,它们才能真正拼成一个完整的世界。
在这个逻辑下,智象未来过去在视觉生成领域积累的能力——比如高可控生成、一致性控制、跨任务建模能力——才真正变成了“能用在具身智能上的底层能力”。
在新的框架中,生成不再只是“做更多数据”,而是在同一个系统里进行一种更严格的过程:既保证空间结构不乱、时间逻辑连续,又保证动作和物理反馈之间是对得上的。
因此,这次合作本质上也被重新定义了:它不只是数据问题,而是一次对“统一建模能力”的真实验证。
通过统一空间中的生成机制,让真实动作在扩展过程中仍然保持物理一致性,不被放大、不被扭曲,从而保证这些数据真正可以用来训练机器人。
而这种能力,也正在被持续验证,并不断迭代升级。
就在2026年4月26日,智象未来在第四届中国(安徽)科技创新成果转化交易会上,正式发布了新一代原生全模态世界模型架构及图像大模型HiDream-O1-Image。

这次发布的意义,不只是“模型变强了”,而是它标志着UiT这条技术路线进入了系统级落地阶段。
该模型基于UiT统一架构构建,闭源版本达到千亿级参数规模,在六项主流Benchmark中达到SOTA,超过Google Banana 2、GPT-Image 1和Seedream 4,处于全球领先水平。同时,智象未来也发布了8B开源版本,在多个任务上表现接近甚至略优,并支持本地部署和低代码应用场景。
这种变化带来的直接结果有两个:一是由于信息链路更短、损耗更少,模型在空间结构和细节控制上更精确,可控性更强、颗粒度更细;二是模型不再被单一模态任务所限制,可以在同一架构下同时支撑更多下游能力,比如图像编辑、视频修改,进一步延展到3D交互与机器人控制等任务,都不需要切换不同模型体系。
更重要的是,这次发布说明了一件更底层的变化:模型能力的提升,不再只是“数据更大、参数更多”,而是在走向一个新的方向——是否能够在同一个表示空间里理解世界。
在UiT架构中,文本、图像、视频、动作和传感器信号被统一放进同一个系统里处理,使模型第一次具备跨模态的“连续理解能力”,而不是简单的模态对齐。
换句话说,模型不只是能处理不同类型的数据,而是开始理解同一个世界在不同情况下的变化规律。
而当这一点发生变化时,真正变化的,其实不是模型本身,而是我们如何定义问题。
在具身智能这种场景中,这一点会变得非常明显:问题不再是“有没有足够数据”,而是“系统能不能在同一个框架里,同时约束真实世界和生成世界”。
而这,也正是智象未来正在回答的问题——通过原生全模态世界模型架构,让机器不仅能生成世界的样子,更开始理解世界是如何运作的。
02 从视觉生成到全模态:智象的独特路径
目标听起来宏大,但落到技术层面,它必须被拆解成一系列可构建、可验证的能力。那么,这种原生全模态世界模型架构,究竟意味着什么?
在智象未来创始人梅涛博士那里,答案被拆解为三个层层递进的核心要素。
第一,全模态表达。不是“支持多种模态”,而是从底层把视觉、动作、传感器、天气……所有信息放进同一个空间里原生处理。世界从来不是分模块运行的,模型也不该。
第二,因果推理。不能只是“世界的视觉模拟器”——看得见画面,却不懂为什么杯子会碎。真正的世界模型必须结合物理规律和因果关系做严密推理,而且经得起验证。
第三,构造世界。人们常说“model the world”,但梅涛博士认为更应该是“mold the world”。你如果不能创造这个世界,你就不能真正理解它。
这三层,从表达到推理到构造,是一个递进:看得全,想得深,做得真。
为什么要走这条路?
因为一个更根本的判断在前面挡着:没有强视频底座,具身智能很难走远。
这句话是梅涛博士反复强调的。在他看来,很多具身智能公司低估了一件事——如果你没有一个能理解物理世界、生成高精度视频的底层模型,那么无论你采集多少遥操作数据,机器人的“理解力”依然会卡在表面。它学到的只是“动作映射”,不是“世界运行的方式”。
放眼全球,世界模型正在形成三条主流路线。英伟达押注“仿真基础设施”,用高保真数字环境做训练场;李飞飞推动“空间智能”,聚焦三维感知与理解;杨立昆追求“认知架构”,试图从底层重建因果推理。路径不同,目标一致:让AI从“数字智能”走向“物理智能”。
智象未来没有复制其中任何一条。
它的路线更接近于:从视觉生成出发,让模型在大规模生成中逐步学会理解世界。 别人是先造“训练场”、造“眼睛”、造“大脑”,再产生数据;智象未来则是先用生成能力解决最现实的“燃料”问题,再沿着这条能力主线向上生长。这是一条更“反直觉”但更务实的路径——不是先搭好世界再填充数据,而是在生成数据的过程中,倒逼模型理解世界。
为什么是智象能做到这件事?
答案藏在三个关键词里:进入早、技术深、基模能力完整。这三个词,恰好也是通向世界模型的入场券。
进入早。2017年,当大多数人还在把视频生成当作“内容合成”时,梅涛博士在微软亚洲研究院就带队做出了全球最早一批文本生成视频模型,并拿下ACM顶会最佳论文亚军。这个认知起点决定了智象未来从一开始就不是在做“单点应用”,而是在思考一个更底层的问题:视频生成,最终要回答的不是“画面好不好看”,而是“模型对世界的理解准不准”。
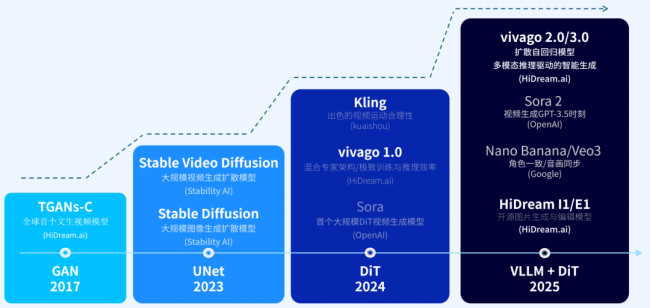
技术深。从2023年8月的UNet到2024年12月的DiT,再到2025年10月VLLM+DiT融合,2026年4月Pixel DiT——每一步都踩在视觉生成技术迭代的关键节点上。但真正的验证来自开源社区:HiDream-I1上线24小时即在Artificial Analysis登顶,成为首个跻身全球第一梯队的中国自研生成式AI模型;全球下载量超200万次,被开发者称为“图片模型领域的DeepSeek”。更重要的是,当别人都在追求“好看”时,智象未来走的是“高可控”——严格遵循物理参数,生成与底层数据精准对齐的画面。这条更难的路,恰恰是具身智能和世界模型所必需的。
基模能力完整。相比很多依赖现成预训练模型、只做垂直微调的团队,智象未来本身就是一家具备基模训练能力的大模型公司。它知道怎么搭架构、怎么训模型、怎么把图像、视频、动作放进同一套系统里。这种能力已经在商业场景中被反复验证:HiBurst跻身TikTok前五大AI合作伙伴;“帧赞”累计制作短漫剧超5000分钟;vivago.ai积累了超3000万全球注册用户。
三层能力叠加,构成了一个很少见的组合:进入早,所以知道路往哪走;技术深,所以走得通;基模能力完整,所以能规模化地走。
也正是这种组合,让智象未来敢于把下一步押在“原生全模态世界模型”上——用统一架构去表达、理解和生成真实物理世界,而不是把图像、视频、文本能力简单拼接在一起。
这不是一个突兀的转向。它是认知、技术与能力累积到一定阶段后的自然延伸。
03 更大的棋:从“训练机器”到“塑造世界”
智象未来真正瞄准的,从来不是“帮机器人多走两步”。它指向一条更长的逻辑:当AI从理解世界走向构造世界,视觉生成的定义将被彻底重写。
这盘棋,可以被压缩成三步,但每一步,都是一次关键换挡。
第一步,落在现实约束最紧的地方——具身智能的数据与训练闭环。通过“真实+生成”的方式扩展高质量数据密度,不只是补数据,更是在验证一件关键问题:生成模型是否真的能在物理世界约束下成立。
第二步,是从“多模态拼接”走向“原生全模态”。过去的模型是在做拆解与对齐,而UiT尝试做的是“从一开始就不拆”。文本、图像、视频、动作与传感器信号,共同生长在同一个表示空间里,以“世界状态”而非“数据类型”组织信息。这意味着模型第一次不再翻译世界,而是直接进入世界的结构本身。
第三步,才是这盘棋真正的分水岭:从“model”走向“mold”。“model the world”,仍然是在理解与预测世界;而“mold the world”,则意味着进入世界内部,重写它的生成规则。
这一步的外沿远比具身智能更大。
自动驾驶会从感知决策走向世界模拟,科学研究会从数据分析走向系统推演,复杂物理与生命系统也可能第一次被纳入同一套可计算框架。
智象未来落下的每一子,都在回答同一个问题:AI究竟能对真实世界做什么?
答案正在浮出水面:不是生成画面,不是理解场景,而是 mold the world。





